

Reward Modeling for RLHF
An introduction to reward models


Introduction
Reward modeling - it’s an essential part of RLHF training pipelines, yet it doesn’t get even a fraction of the attention of other LLM topics like prompting, supervised fine-tuning and data collection. In this post we’ll take a closer look at reward modeling and shed some light on this dark corner of RLHF. All top-performing Large Language Models (LLMs) like GPT-4 and Llama 2 used reward models as part of their training pipelines. A notable exception from this are recent LLMs trained with Direct Preference Optimization (DPO), which doesn’t require a separate reward model for LLM training - more on that later.

Reward modeling is an intermediate step in the LLM training pipeline and the reward model usually isn’t published alongside the trained language model. Think of a reward model as the movie director - you can’t see it in the final product, yet its impact is undeniable. Quoting from the Llama 2 paper: “We note that reward model accuracy is one of the most important proxies for the final performance of Llama 2-Chat”. This will make sense once we understand the role which the reward model plays in the RLHF training pipeline. From the perspective of classical Reinforcement Learning, reward models have a role similar to that of the critic in actor-critic algorithms, with the main difference being that critic models are usually trained online in parallel with actor training, while the reward models are usually trained offline and held fixed during the LLM fine-tuning (or re-trained a handful of times if several rounds of human feedback collection are performed, like in the Llama 2 paper).
So what is a reward model? It takes a prompt and a response as inputs and returns a single scalar - the predicted quality of the response. It is based on the same architecture as the language model (transformer), but the unembedding (output) linear layer of size (Embed_dim, Vocab_size) is replaced by another linear layer of size (Embed_dim, 1), which outputs the scalar predicted reward (see Figure 2). Optionally, a special reward readout token can be used. The predicted reward is read out from the output of the reward head at the last token of the response. Since the reward is read out just once for the whole response, it can only score the whole response, not individual tokens or partial responses. A pre-trained (e.g. SFT) language model weights are used to initialize the reward model weights to speed up training.

Reward Model Applications
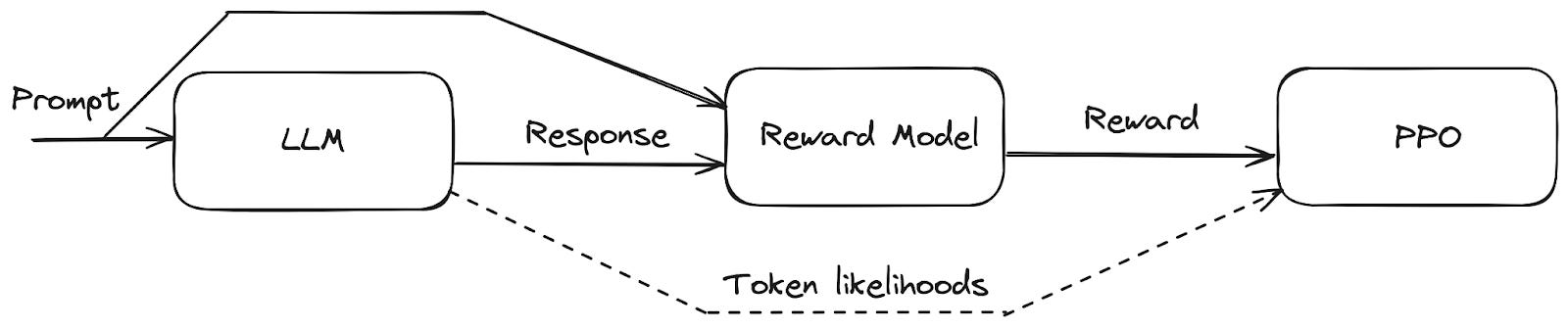
To better understand the role of the reward model in RLHF training, let’s take a closer look at Proximal Policy Optimization (PPO) - the de-facto standard RLHF algorithm. PPO is an online RL algorithm - it requires live interaction with the environment to close the state->action->reward loop. The environment takes action as input and returns the reward and next state. To truly align with human preferences, we could show the model’s responses in real time to human raters and use their ratings as reward for training (with a caveat that PPO needs scalar reward, so we’d need some processing to turn relative preferences into scalar rewards). But this would be logistically impractical, so the trained reward model is used as a proxy for the environment during PPO training and we pretend that the reward predicted by the reward model is the true quality of the response. This points to one of the biggest problems in RLHF - the trained reward model is an imperfect representation of true human preferences and it’s easily overoptimized by RL, which is known to exploit imperfections in reward model definition in the spirit of Goodhart’s law. More on this at the end of the post (and even more in a separate upcoming post). Figure 3 shows how the reward model plugs into the PPO training loop.
Reward model has some similarity to model-based RL, but the similarity is superficial because in RLHF the reward model is used to score complete responses, while in model-based RL the models are used for multi-step trajectory planning. While the application of reward models to LLM tuning is a recent phenomenon, reward modeling for RLHF was first demonstrated at scale back in 2017 in an OpenAI paper in application to classical RL environments like Atari.
Reward models have a few more important applications - (1) turn relative preferences into scalar rewards, (2) offline evaluation; (3) ranking. First, typical RLHF pipelines collect human preferences in the form of relative preferences (response A > response B), while PPO requires a scalar reward. We can use the Bradley-Terry model to turn these relative preferences into continuous scalar rewards (more on this in the next paragraph). Second, the reward model estimates the quality of a response, so it could be used for offline evaluation of language models. The main thing to be careful about with offline evaluation is to prevent data leakage - the reward model used for offline evaluation should be trained on a separate dataset with no overlap with LLM training data. Finally, the reward model can be used to rank multiple LLM generations and choose the best one. This is sometimes known as “best-of-n” in RLHF literature (e.g. RRHF paper). The ranking can be done either at inference time (pros: no LLM fine-tuning required; cons: high inference compute cost because multiple generations are required) or at training time (e.g. RAFT paper).
Reward Model Training
The most popular method of training the reward model is based on the Bradley-Terry model, which assumes that each response has an unobserved intrinsic quality u and the probability that a rater prefers option i to option j is equal to:
This probability can be incorporated into a log-likelihood-based loss to train the reward model using pairs of responses to the same prompt labeled as better/worse. Note that in the Bradley-Terry model the qualities are defined up to an additive constant because (u_i-u_j)=((u_i+C)-(u_j+C)). This means that each individual quality score isn’t interpretable by itself and only has some meaning when compared to other scores. In practice, after the reward model is trained, its output can be normalized by adding a bias term, so that the reward scores have 0 mean on the training data. This isn’t strictly necessary, but normalizing the scores can help reduce the variance during PPO training.
The Bradley-Terry model is closely related to the Elo rating system, and the reward model scores have the same properties as the Elo scores (up to scale/offset transformation). There’s several more advanced implementation options for the Bradley-Terry model. In the InstructGPT paper, K>2 responses are given to labelers and they are asked to rank the whole list, resulting in (K choose 2) pairwise comparisons, each of which is represented by a separate term in the loss function. This is reported to speed up data collection because each response can be compared to several other responses independently. In Llama 2 paper, confidence-based margin is added to the loss. The intuition here is that the difference between the reward model scores of better and worse options should be higher for pairs in which we have high confidence in their relative order, and can be lower if we’re not sure which of the options is really better.
An alternative way to train a reward model could use a regression loss with scalar reward labels. For example, if we want to train an LLM to write tweets which get as many likes as possible, we could use the number of likes on a tweet as the reward label and train a reward model to predict this continuous label using an MSE loss. Another possible option is to use the outputs of existing classifiers as reward scores. For example, in this paper an existing aesthetic classifier was used as a reward model for PPO training. Similarly, existing classifiers can be used as reward models to fine-tune the models to reduce hallucinations, improve conciseness, etc. Using feedback from classifier as a reward isn’t technically RLHF, but it’s close enough in spirit and in implementation details.
RLHF without Reward Models
But do we REALLY need the reward model for RLHF? The authors of DPO paper show an attractive way to do something that looks very similar to RLHF (the debate is still on about whether DPO matches the “RL” part of RLHF), but without a separate reward model. Instead, they use a clever mathematical trick to derive the implicit reward model scores based on the LLM token likelihoods. This trick allows them to derive a loss which looks like a mix between reward model and language model losses. The jury is still out on whether DPO is the future of RLHF, but we start seeing more and more state-of-the-art LLMs like Zephyr and Solar trained with DPO instead of PPO. The DPO vs PPO debate deserves more space than I can afford here, but Nathan Lambert has several very insightful blog posts about DPO: blog post 1, blog post 2 - I highly recommend them to anyone who’s interested in this topic.
Open Questions
Reward modeling for RLHF appeared relatively recently and has received less attention than language model training, so there are still plenty of open questions left. The most interesting ones, in my opinion, are:
Credit assignment. The reward model evaluates complete responses, but they are actually generated token-by-token. The current PPO implementation used in RLHF side-steps this problem by using a “bandit” formulation, in which the whole response is considered to be a single action by the agent. If we could assign granular rewards to individual tokens (or sub-sequences) in the response, we could use more powerful RL methods to perform forward-looking planning during token generation.
Preventing overoptimization. Naively applying PPO to a trained reward model will result in reward model scores increasing significantly during training, while the quality of the text will actually degrade. This is a result of overoptimizing to an imperfect learned reward model. Preventing this overoptimization is one of the biggest questions in RLHF right now. A wide range of approaches has been proposed, but it’s unclear which of them work best: regularization (KL divergence, supervised or unsupervised language modeling losses), model ensembles, constrained optimization, early stopping. This is a very deep and interesting question, deserving a dedicated post. Stay tuned!
Beyond Bradley-Terry. The ubiquitous Bradley-Terry model makes several simplifying assumptions: (1) pairwise preferences are determined by underlying single-item qualities; (2) the single-item qualities are scalars (no multidimensional preferences); (3) the pairwise preferences are stochastic with probabilities equal to the sigmoid of difference in qualities. While these simple assumptions are a good place to start, the field of Behavioral Economics has conclusively shown that human preferences are very complex and can include effects like anchoring, framing, loss aversion, etc. which contradict the Bradley-Terry model. A few recent papers like IPO and HALO have relaxed these assumptions and showed promising results.
Evaluation. How do we know if our reward model is good enough? The most common metric here is pairwise accuracy - the fraction of pairs of responses in which the better option has a higher reward model score than the worse option. This is a useful metric, but it misses important aspects like the magnitude of the difference in scores. Also, it’s unclear what kind of evaluation metrics could describe specifically whether the reward model is suitable as a reward for PPO training.
References
Touvron, Hugo, et al. "Llama 2: Open foundation and fine-tuned chat models." arXiv preprint arXiv:2307.09288 (2023).
Rafailov, Rafael, et al. "Direct preference optimization: Your language model is secretly a reward model." arXiv preprint arXiv:2305.18290 (2023).
Christiano, Paul F., et al. "Deep reinforcement learning from human preferences." Advances in neural information processing systems 30 (2017).
Tunstall, Lewis, et al. "Zephyr: Direct distillation of lm alignment." arXiv preprint arXiv:2310.16944 (2023).
Kim, Dahyun, et al. "SOLAR 10.7 B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling." arXiv preprint arXiv:2312.15166 (2023).
Dong, Hanze, et al. "Raft: Reward ranked finetuning for generative foundation model alignment." arXiv preprint arXiv:2304.06767 (2023).
Yuan, Hongyi, et al. "RRHF: Rank Responses to Align Language Models with Human Feedback." Thirty-seventh Conference on Neural Information Processing Systems. 2023.
Hao, Yaru, et al. "Optimizing prompts for text-to-image generation." arXiv preprint arXiv:2212.09611 (2022).
Azar, Mohammad Gheshlaghi, et al. "A general theoretical paradigm to understand learning from human preferences." arXiv preprint arXiv:2310.12036 (2023).