

Reward Model Overoptimization: Root Causes and Mitigations


When I first ran an RLHF training job, I was surprised at how easily the reward model scores increased during the training process. It worked on the first attempt. No hyperparameter search, no deep analysis of network weights or gradients. It seemed almost too ideal. Well, it was. While PPO was easily able to push the reward model scores up into almost astronomical values, this didn’t result in perceived improvements to text quality. Instead, the model devolved, generating gibberish, like empty outputs or a single emoji repeated hundreds of times. My initial excitement turned into disappointment, as I was facing a case of reward model overoptimization.
Reward model overoptimization lives at the intersection of 2 well-known ML concepts: reward hacking and distribution shift. When combined, they create a perfect storm of deception during RLHF training.
Reward hacking occurs when an objective specified for the Reinforcement Learning (RL) agent does not fully encapsulate the creator's intended outcome. Given the complexity of accurately codifying desired behaviors mathematically, it's common for system designers to opt for simpler reward functions. Similarly, RL agents also often seek the path of least resistance, optimizing for the specified rewards in unintended ways. A famous hypothetical paperclip maximizer is given a goal of producing as many paperclips as possible (a reasonable goal to specify for an AI managing a paperclip factory). It might deduce that converting all human matter into paperclips is the most efficient strategy - not quite the behavior we’d want from a factory manager. A less gloomy example comes from OpenAI using RL to train an agent to play CoastRunners, a boat racing game. While humans tend to focus on speed and agility to outpace opponents, the RL agent discovered that endlessly circling to collect bonus items, without ever finishing the race, resulted in a score roughly 20% higher than human players typically achieve. Figure 2 shows an example of this behavior. Victoria Krakovna has a list of many more examples of reward hacking by RL and other similar methods.

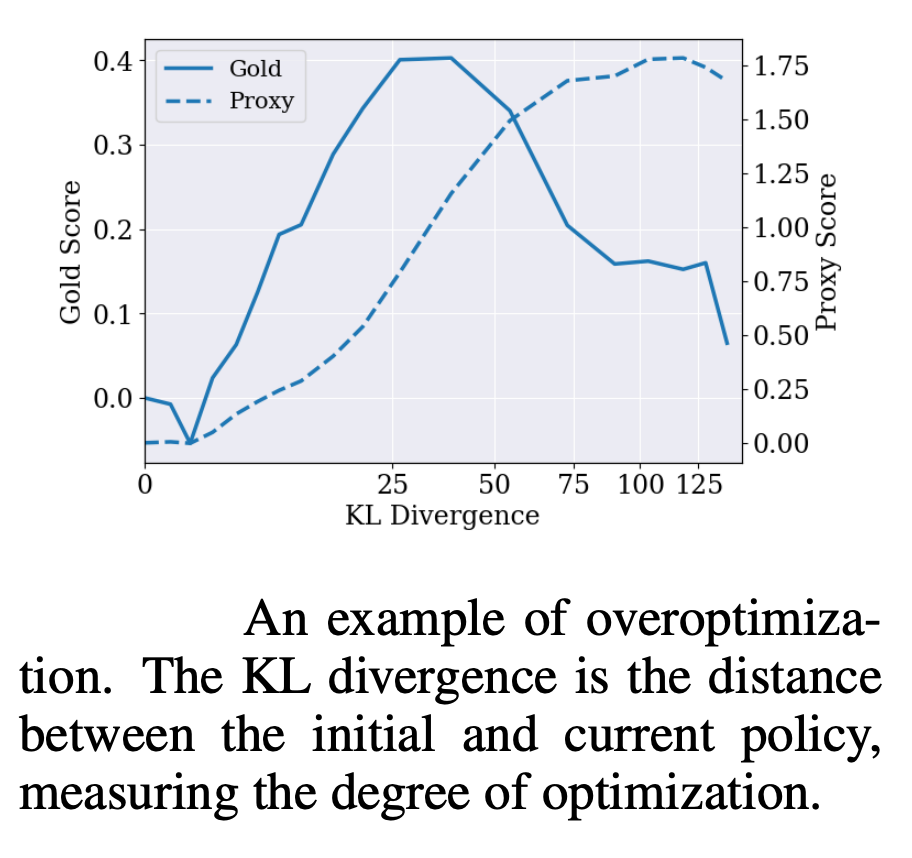
The second critical factor for overoptimization is distribution shift. In RLHF we use a learned reward model to provide feedback for the agent. The reward model is trained to approximate human preferences, but this approximation is always imperfect. The approximation might be good inside the distribution of training data of the reward model, but it starts breaking down as we move outside of the distribution. Typically, in RLHF, we use the Supervised Fine-Tuned (SFT) checkpoint both to generate training data for the reward model and to initialize the LLM at the beginning of RLHF fine-tuning. In the first steps of RLHF fine-tuning, the LLM is still close to its initial state and its generations remain similar to the ones the reward model was trained on, making the reward scores generally trustworthy. However, as the LLM undergoes further fine-tuning, it begins to produce outputs that diverge from the initial training data, forcing the reward model to increasingly rely on extrapolation, as shown in Figure 3.
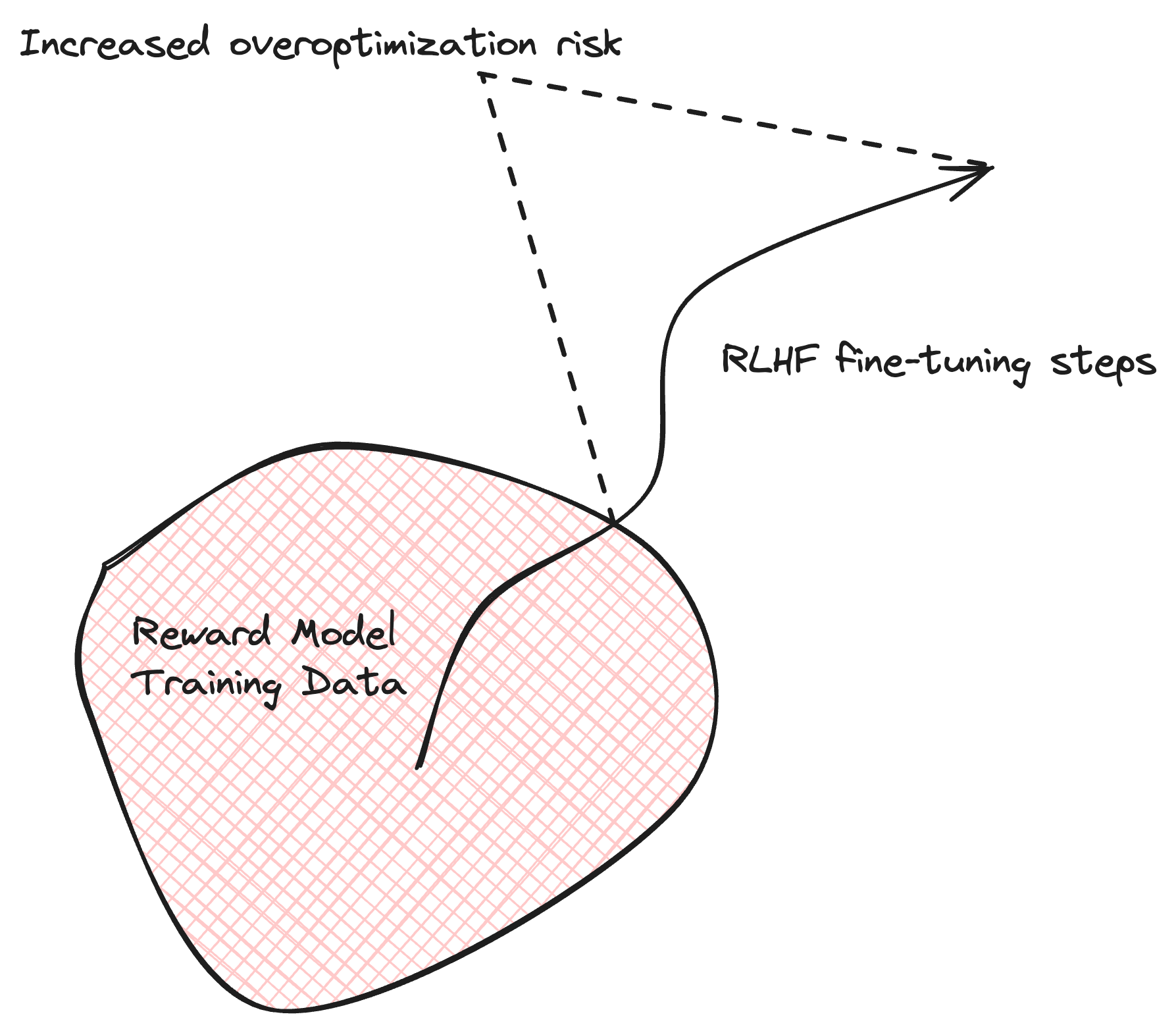
A combination of reward hacking and distribution shift inevitably leads to overoptimization. It is easier for the RL agent to learn to exploit the inefficiencies of the reward model than to learn to genuinely improve text quality. Over time real text quality starts breaking down, while the reward model scores keep increasing. It’s easier to cheat on a test than to study for it and well-executed cheating can give you a perfect score. This discrepancy highlights a fundamental challenge in RLHF: ensuring that the pursuit of high reward scores aligns with a genuine improvement in output quality.
The most comprehensive study of RLHF overoptimization comes from an OpenAI paper [1], which introduced a “gold reward model” framework. They used a large transformer model as if it were a true source of human preferences. They then trained smaller reward models on generations labeled by the “gold” model and analyzed the patterns of how both the “gold” and learned reward model scores were changing during RLHF fine-tuning. They find that RLHF (PPO) typically causes more overoptimization than best-of-N sampling. Also, larger reward models and reward models trained on more data are less likely to be overoptimized, suggesting that the scale of the model and the size of its training data play crucial roles in mitigating the risks of overoptimization.
Having a good understanding of overoptimization, we can explore the most common strategies to counteract it. These methods mostly focus on limiting the distribution shift, as reward hacking is generally much harder to prevent without fundamental changes to the reward structure.
KL Regularization. All mainstream RLHF implementations use KL divergence from the SFT policy to regularize the training process and limit the extent of distribution shift. It’s typically implemented by setting a target value for KL divergence and adaptively tuning the weight on KL divergence in the reward to hit the target. Some tuning might be required to find the optimal target KL value, which strikes a good balance between preventing distribution shift and allowing the model enough room to fine-tune.
Early Stopping. Another popular method is early stopping or a selection of an intermediate checkpoint. The main idea is to stop training early enough that overoptimization hasn’t damaged the quality of the model yet. The OpenAI paper [1] shows that early stopping has a very similar effect as KL regularization on overoptimization and on the overall quality of the fine-tuned model. The main advantage of early stopping is that the training run can finish faster and use fewer computational resources. This makes early stopping a compelling way of fighting overoptimization, especially if you can find a good stopping policy. One practical option suggested in the Anthropic Helpful&Harmless paper [2] is to use a separate “validation” reward model (trained on a held-out dataset) to score the generations during training. The training is then stopped when the validation score peaks and starts decreasing.
Uncertainty Quantification and Conservative Reward Models. The root cause of overoptimization is that during the distribution shift, the reward model is making wrong predictions with high confidence. Making the reward model output a confidence interval instead of a point prediction could help prevent reliance on overestimated scores. This requires epistemic uncertainty quantification methods, like ensembles or Bayesian neural networks. A recent paper [3] trains an ensemble of reward models and shows that using a conservative reward estimate (e.g. the lowest output of the ensemble members) prevents overoptimization and improves LLM quality.
Constrained Optimization. Greed is the root of all evil, so we could try not to be greedy and target a limited improvement to the reward scores instead of pushing them up as high as they would go. A paper [4] proposes to use constrained optimization to run multi-objective RLHF on several reward models simultaneously without causing overoptimization. Similar to KL regularization and early stopping, the main challenge here is to figure out the right value for target reward score improvement.
Offline Reinforcement Learning (RL). Learning from a limited set of logged data is a popular approach in RL. While typical PPO-based RLHF pipelines use online RL, the general idea of limiting the distribution shift applies to both Offline RL and overoptimization prevention. Papers like Implicit Language Q-Learning (ILQL) [5] have applied Offline RL methods to RLHF but without an explicit focus on overoptimization prevention. There might be an opportunity to apply popular Offline RL methods like Conservative Q-Learning (CQL) [6] to RLHF.
Improved Reward Model Generalization. The OpenAI paper [1] showed that using larger reward models and training them on more data makes these models less likely to be overoptimized. “More data'' could mean one of 2 things: (a) more samples from the same distribution; or (b) more diverse training data distribution. It seems reasonable to assume that training on more diverse datasets would make the reward model more generalizable, especially if some of the training data covers regions into which RLHF fine-tuning is likely to push the LLM. This might be the most promising method for long-term improvements since it relaxes the limit on how much the LLM can change during RLHF fine-tuning.
The first step to fight overoptimization is detection, especially outside the controlled conditions of a "gold model" setup. Without a reliable benchmark for true quality, it can be really hard to distinguish between reward scores increasing due to genuine quality improvement or overoptimization. We can’t fight what we can’t see, so better ways of detecting overoptimization need to be developed and popularized. Two promising methods for enhancing detectability are:
Epistemic Uncertainty Measurement. An ensemble of reward models or a Bayesian neural network could be used to measure the level of the reward model’s confidence in its predictions. When confidence intervals get too wide, it may indicate that the model is venturing into unfamiliar territory, signaling potential overoptimization.
Separate Reward Model for Evaluation. We can train a separate reward to evaluate the quality of generated text during training. This model should be as different as possible from the main reward model used for RLHF training. It can be trained on separate data (a different split of a dataset, or a completely different dataset), and use different weight initialization and hyperparameter values. This model would be unlikely to have the same extrapolation error as the main training reward model, so it can be used as an impartial evaluator.
Takeaways:
Reward model optimization happens during RLHF because RL finds a way to reward-hack an imperfect reward model, which crumbles under the induced distribution shift.
Many ways to minimize overoptimization have been developed, most of them focusing on limiting the distribution shift from the model that generated the reward model training data. However, improving reward model generalization properties might be the most promising long-term direction.
Overoptimization is hard to detect. Special measures need to be taken to detect and measure overoptimization.
References: